
AI vs machine learning vs deep learning vs generative AI, in plain English


December 30, 2025
Prefer to watch this instead?
In this blog, we focus on how these ideas show up today in real products and tools. That means we simplify a few things on purpose. It keeps the big picture clear and avoids pulling beginners into edge cases that, while interesting, are not very helpful for anyone just trying to get a high-level view of these terminologies.
Think of these terms as a set of nested ideas, like boxes inside boxes.
- Artificial Intelligence (AI) is the broader field
- Machine Learning (ML) is a subfield of AI
- Deep Learning is a subfield of ML
- GenAI is a subfield of Deep learning
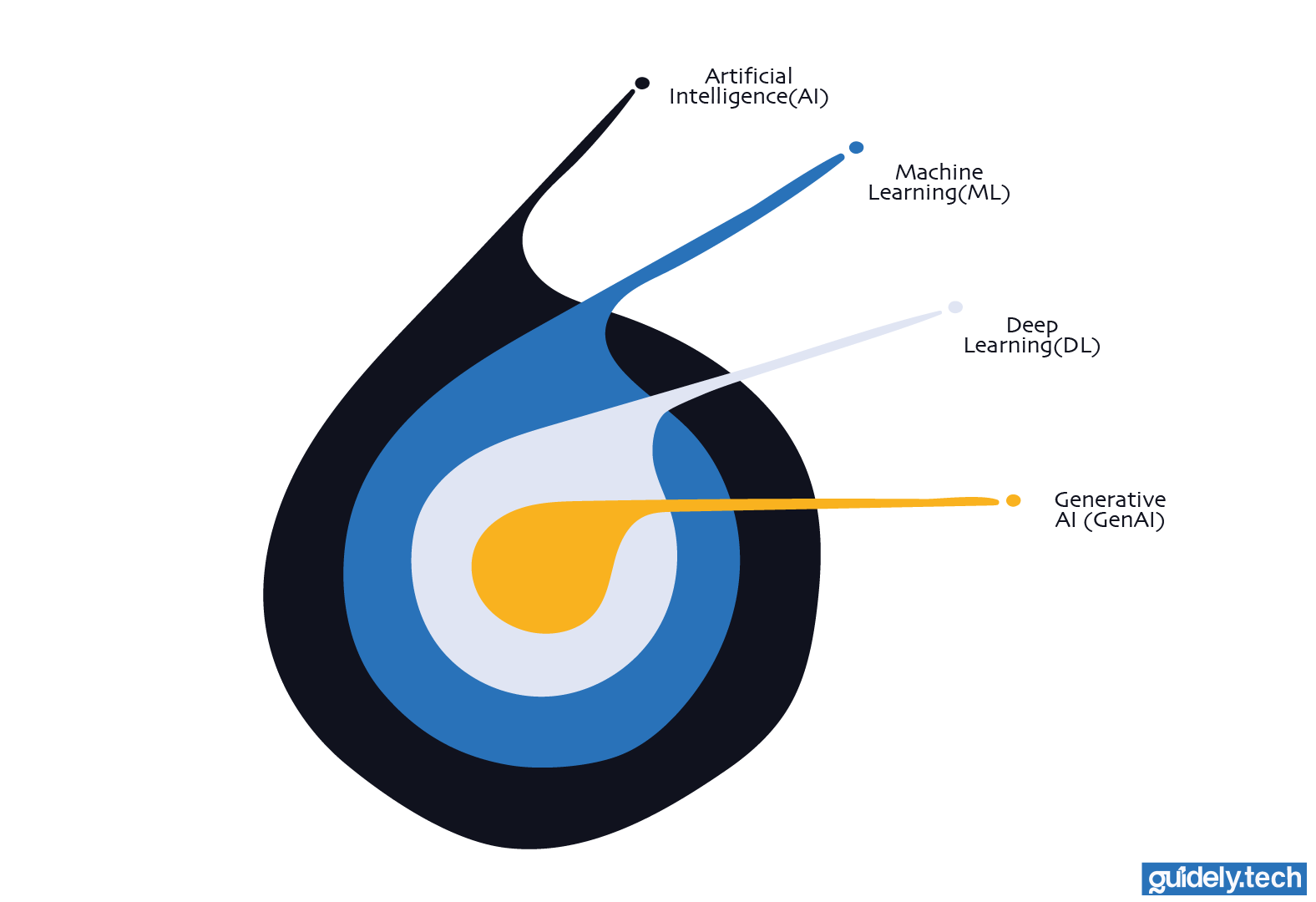
AI vs machine learning vs deep learning vs generative AI: The differences at a glance
- Artificial Intelligence (AI) is the big idea: How can we build machines that learn, reason, adapt, and make decisions like humans?
- Machine Learning (ML) is how we achieve AI. Instead of telling computers exactly what to do, we show them examples and let them learn the rules on their own.
- Deep Learning (DL) is a smarter form of ML. It's still about learning. It just uses networks inspired by the human brain to spot complex patterns.
- Generative AI (GenAI) refers to systems that create new content, like text, images, music, or code, based on patterns they learned from existing examples. Most modern generative AI systems are built using deep learning models. So while generative AI is not formally a subfield of deep learning, deep learning is the main tool that makes today’s generative AI possible.
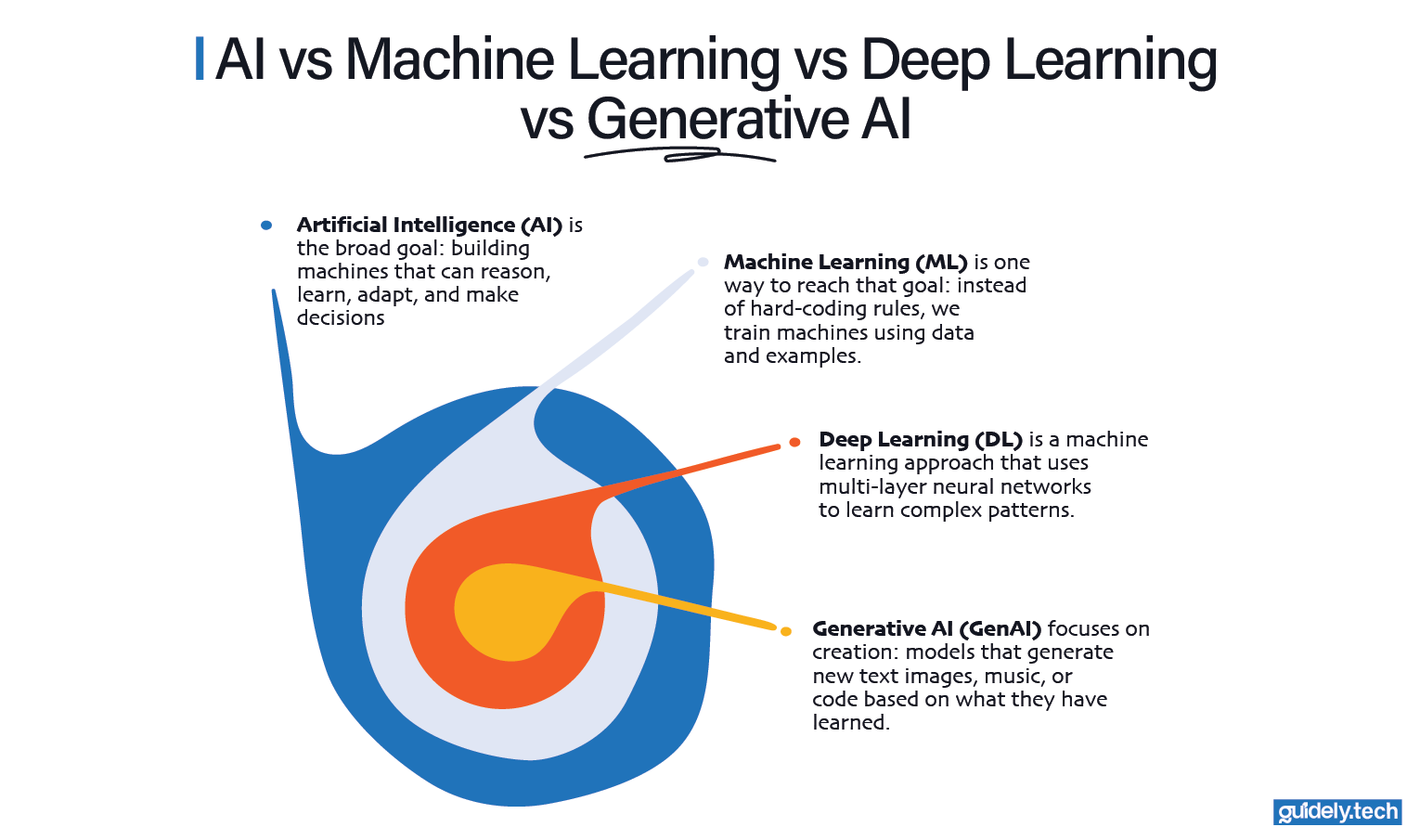
AI vs machine learning vs deep learning vs generative AI: A deeper conversation
Artificial Intelligence (AI): The big umbrella
AI is the broad field that asks: “How can we make computers learn, reason, adapt, plan, and make decisions?” Abilities that would normally require human intelligence.
How does machine learning (ML) achieve intelligence?
AI is the goal. Machine Learning is one practical way to get there.
Before machine learning, systems were often built with rules. For example, imagine trying to predict house prices using a rule-based system. You might write rules like: “If the house is big, increase the price,” or “If the house is far from the city, lower the price.” Very quickly, the rules become messy. How much does size matter? How much should location affect the price? What if two rules conflict?
With machine learning, we take a different approach. Instead of writing the rules ourselves, we show the system many real examples of houses along with their actual selling prices. Each house is described using measurable features like size, number of bedrooms, location, and age. The model studies these examples and learns patterns on its own, such as how much size or location usually affects price.
This is where intelligence starts to show up. The system is not just following fixed instructions. It is adapting its behaviour based on experience. When it sees a new house, it uses what it has learned from past examples to make a reasonable prediction, even if it has never seen that exact combination of features before.
In other words, machine learning feels intelligent because the system improves by learning from data, not because we told it every rule in advance.
On predictions, please note that: The model’s predictions are most trustworthy when the new house is similar to the homes in the training data; if the location or features are far outside that range (for example, an 11-bedroom villa in California when the model was trained on European homes with no more than five bedrooms), the prediction is likely to be unreliable.
How machine learning works
Traditional machine learning models work by learning the effects of features and their interactions. A feature is a piece of information that humans choose and define ahead of time. In the house price example, these features might be:
- The size of the house
- The number of bedrooms
- The location
- And how old the house is.
Once these features are defined, each house can be represented as a single row in a table. The model then studies many such rows and learns how different feature values tend to affect the final price.
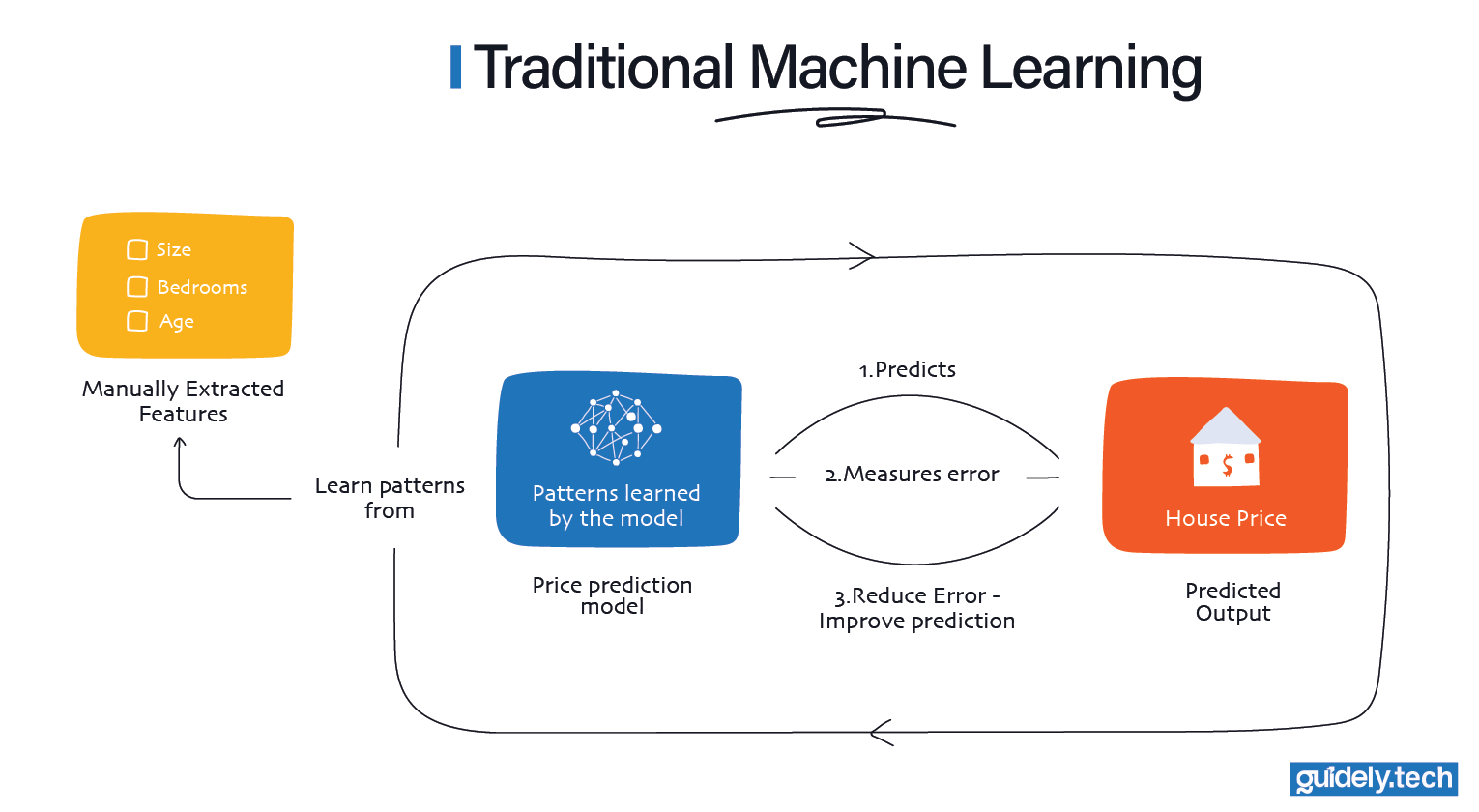
This approach works well when the features are obvious and easy to measure. As long as we can clearly list what matters and store it in a structured format, well-implemented traditional machine learning can uncover useful patterns.
But this is also where its limits show up. When data becomes messy or unstructured, like images, audio, or free-form text, defining the right features becomes extremely difficult. The more complex the data, the harder it is for humans to decide what should count as a feature in the first place.
Traditional machine learning can only learn from the features we provide. When those features fail to capture what truly matters, the learning stalls. This limitation is what led to the rise of deep learning, which approaches the problem differently.
How is Deep Learning (DL) a smarter form of ML?
Deep learning is a special kind of machine learning that uses neural networks, algorithms inspired by how our brains work. In short, Deep Learning = ML done with deep neural networks. But why neural networks?
As hinted earlier, a core limitation of traditional ML models is that as data becomes more complex, the amount of manual feature engineering grows rapidly. Some problems, such as images and text, contain patterns that are too subtle and varied for humans to extract by hand.
Imagine how your phone unlocks when it recognises your face.
With traditional machine learning, a human would first decide what features matter. Things like the distance between your eyes, the shape of your nose, or the width of your mouth. The model then learns how those hand-picked features relate to your identity. If the lighting changes, you wear glasses, or grow a beard, those features may no longer work well, and the system struggles.
With neural networks, the approach is different. Instead of telling the system what to look for, we show the model many photos of your face and let it learn directly from the raw pixels. Over time, it learns simple patterns such as edges and shadows, then more complex ones such as facial features, and finally, what makes your face uniquely yours.
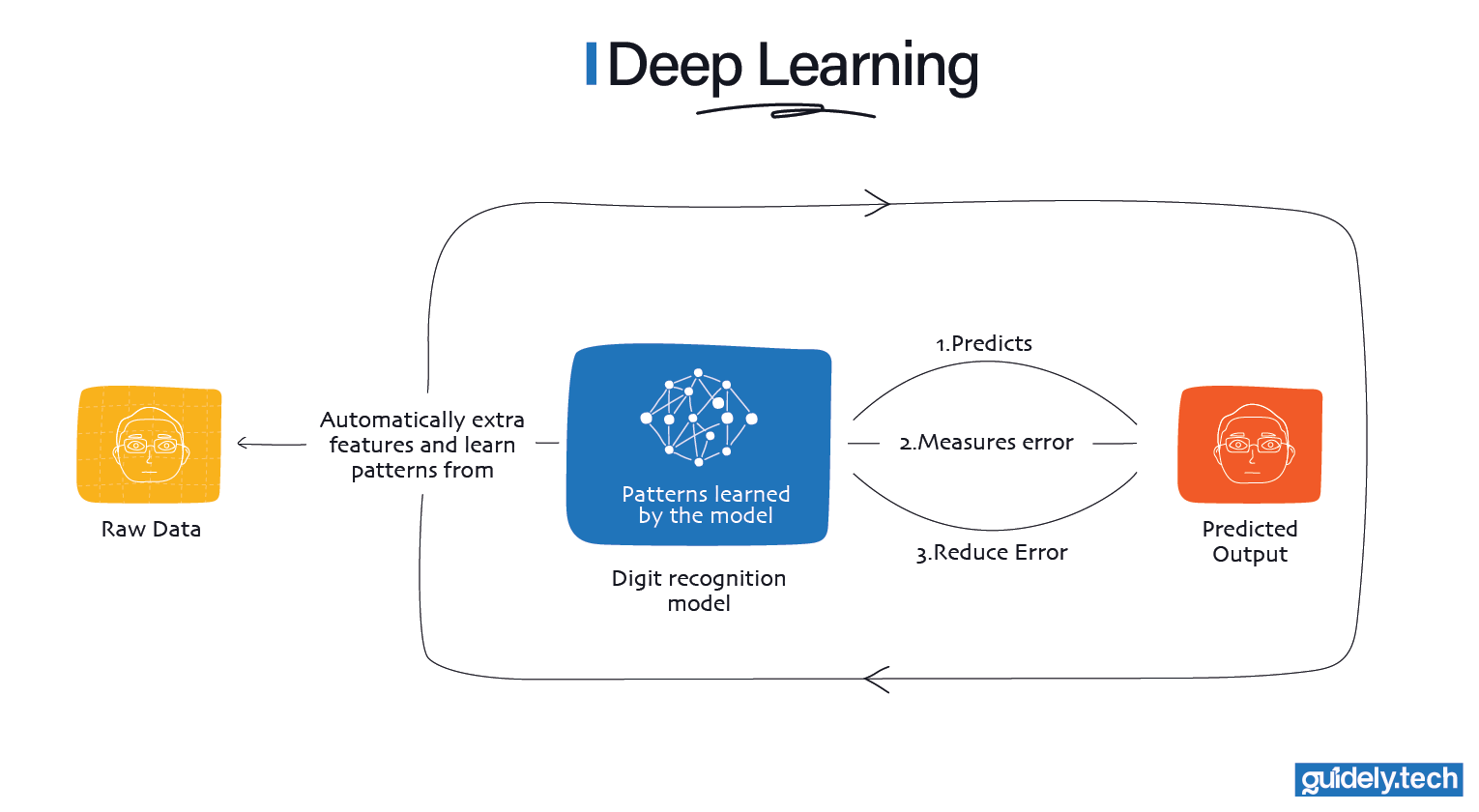
This ability to learn useful features on its own is what allows deep learning to power reliable face unlock on modern phones, and why it is considered a smarter and more powerful form of machine learning.
With a neural network, instead of saying, “Here are the features, please learn from them,” we say: “Here are the pixels(for example) and the correct label. Learn both the features and the patterns by yourself.” This shift is the heart of what makes neural networks different.
As a side note, while Deep Learning allows for processing more complex and unstructured data, the amount of training data required is often larger than for classic Machine Learning, and sometimes consumes more computational power.
Generative AI (GenAI): Generating content
Most of today’s Generative AI systems, like large language models and image generators, are built using deep learning. Even though we call them “generative,” they are still predictive models under the hood**;** They learn by predicting, not by creating.
What happens during training
During training, a language model is shown a huge number of real examples. Text from articles, books, websites, and so on. The goal at this stage is not to have the model generate new content. Instead, it learns by guessing the next word in the text it is given. In reality, language models break text into smaller pieces called tokens. To keep things simple, we will treat a token as a word.
If the training sentence is. “The cat sat on the mat”
The model might be given.
- Input. “The cat”
- Correct next word. “sat”
At first, the model has no idea which word should come next. So it tries to assign a score to every word it knows. These scores reflect how likely each word feels in this position. For example, words like sat, jumps, or chases might get higher scores because they often follow “The cat” in real writing. Words like spaceship or painted might still be considered, but they receive much lower scores because they rarely show up after “The cat” in everyday text. Many other words are nearly impossible here, so they end up with scores very close to zero.
These scores across all known words are what we call a probability distribution. It is just a list of every word the model knows, each with a number showing how likely it thinks that word should come next. A higher number means “fits better here,” a lower number means “fits worse.”
Training is about refining these numbers so the model leans toward the correct word more and more over time. After each guess, the model checks how close its scores were to reality. If the correct next word did not get a high score, the model was wrong. It measures this wrongness as a single number called loss/error. You can think of loss as a score for the model itself. High loss means it was very wrong. Low loss means it was close.
Once the loss is calculated, the model adjusts its internal settings so that next time it is slightly more confident in the correct word and slightly less confident in incorrect words. Each nudge is tiny, but these nudges happen again and again with new examples. Billions of times.
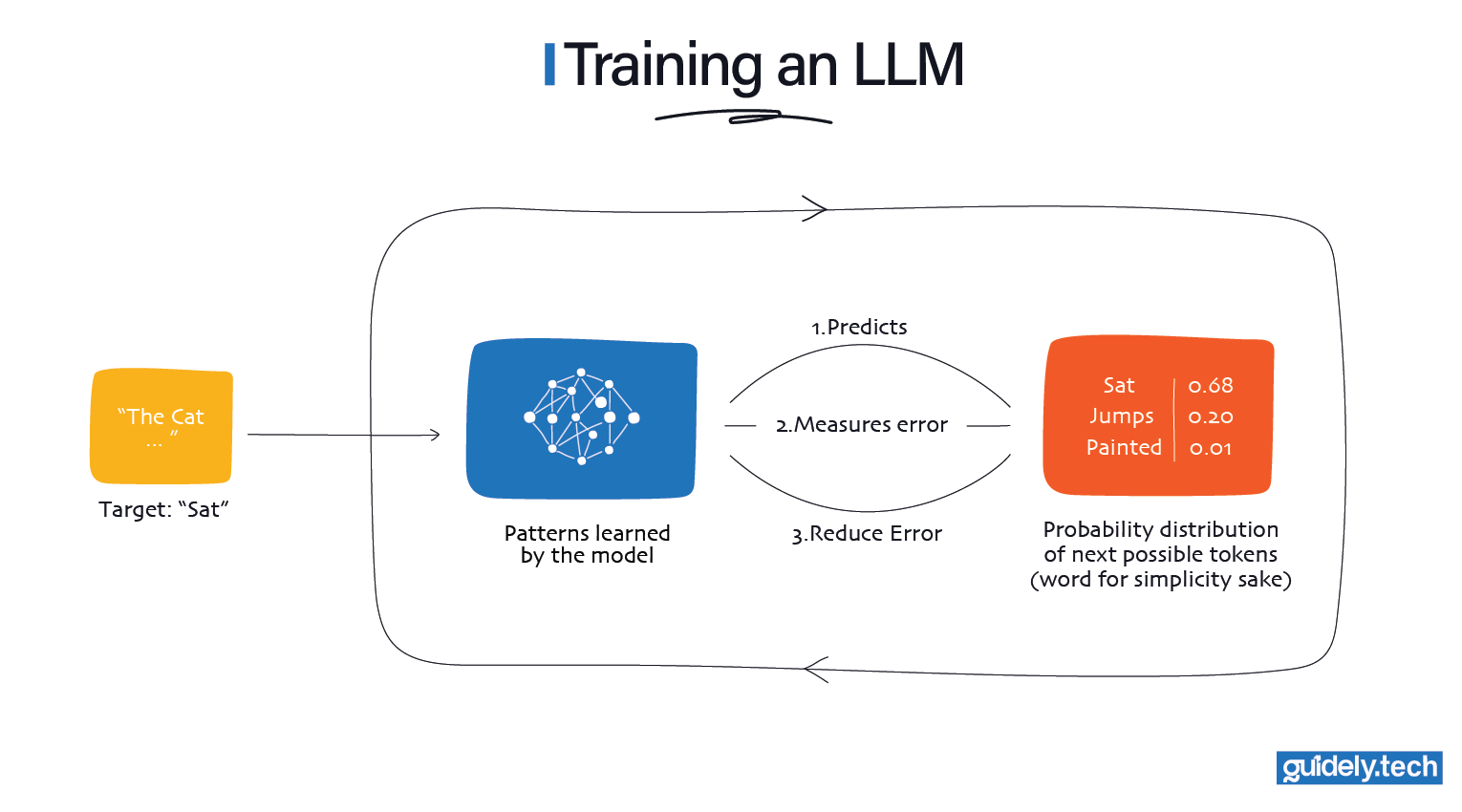
Over time, the model becomes very good at giving higher scores to words that fit naturally in context and lower scores to words that do not. When this happens consistently across many examples, we say the model has learned.
The same idea applies to images. During training, generative AI is not creative. It is learning patterns by predicting missing or corrupted pieces of real data and correcting its mistakes.
What happens after training
Let’s ground the conversation here in the familiar: LLMs.
Once training is complete, we stop updating the model. Its parameters are fixed. Now we switch how we use it. When you ask the LLM to generate something, it does the same kind of prediction it learned during training, but repeatedly.
- You provide a prompt.
- The model predicts the most plausible next words
- One word is selected from the set of plausible next words.
- That word is added to the prompt.
- The model predicts the next word again.
- This loop continues until the model predicts that the text should terminate.
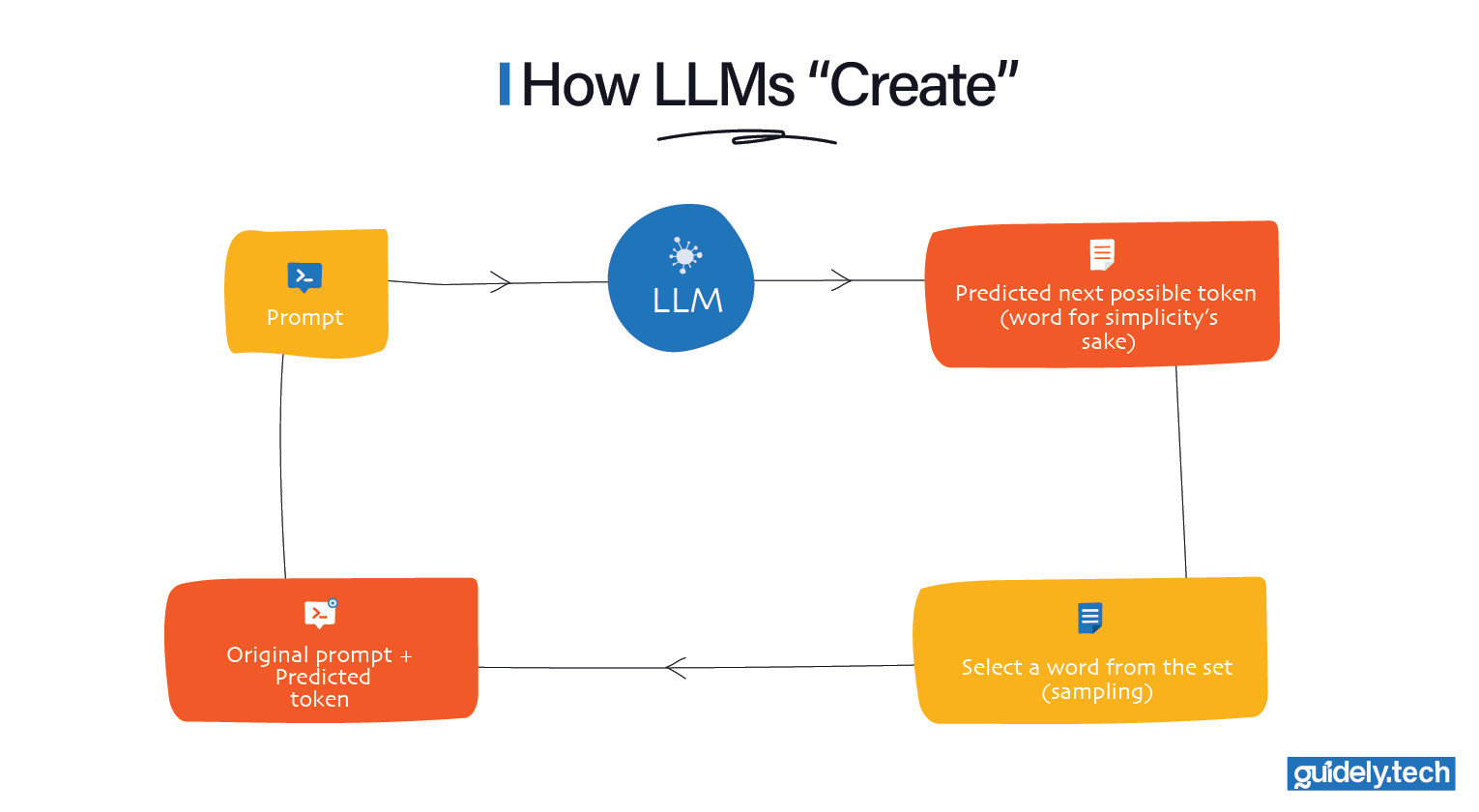
Nothing fundamentally new is happening. It is still predicting the most likely next words, one step at a time. This repeated prediction is what creates the illusion of creativity.
Why outputs feel new and creative
At each prediction step, the model usually has multiple reasonable options.
For example, after: “I hope you are having a…”
The model might assign high probability to:
- “great”
- “nice”
- “wonderful”
A small amount of randomness allows it to pick among these options instead of always choosing the same one. This is why:
- Two answers to the same prompt can differ
- Both answers still make sense
- The output does not feel mechanical or copied
The randomness does not mean the model is guessing blindly. It means it is choosing among several learned, sensible possibilities.
🚗 The Commuting analogy
Here is an analogy to help you understand the relationship between AI, machine learning, deep learning, and generative AI. Like with most analogies, it's not perfect, but hopefully you get the big idea.
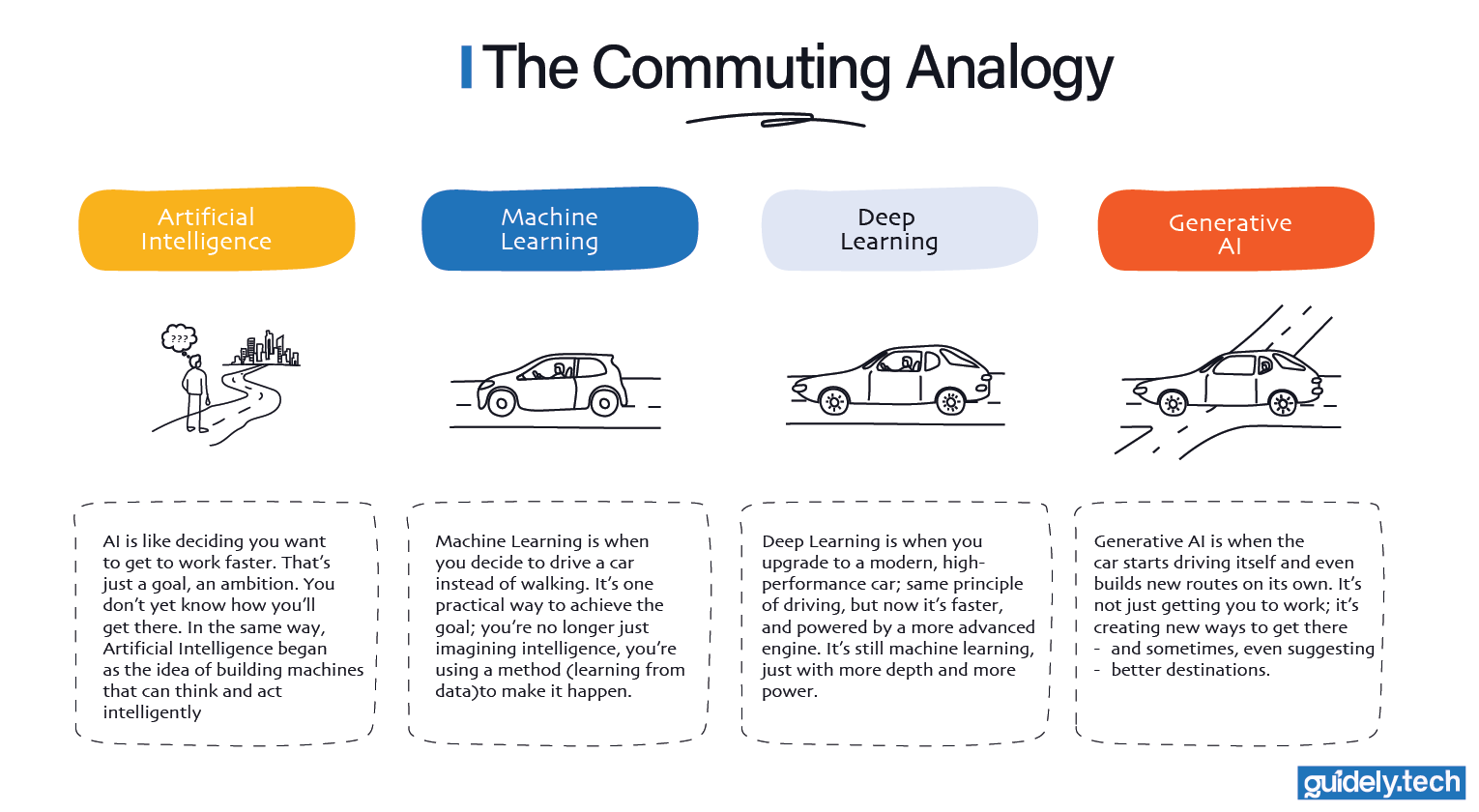
- AI is like deciding you want to get to work faster. That’s just a goal, an ambition. You don’t yet know how you’ll get there. In the same way, Artificial Intelligence began as the idea of building machines that can think and act intelligently.
- Machine Learning is when you decide to drive a car rather than walk. It’s one practical way to achieve the goal; you’re no longer just imagining intelligence, you’re using a method (learning from data) to make it happen.
- Deep Learning is like upgrading to a modern, high-performance car; the same principles of driving, but now it’s faster and powered by a more advanced engine. It’s still machine learning, just with more depth and more power.
- Generative AI is what becomes possible with that modern car. The car can now drive itself, plan routes, and even create new ways to get you to work. GenAI is not a “type of car.” It is what the advanced engine enables. Most of the GenAI we see today runs on deep learning engines, but other engines could exist as well.
Summary Table
| Concept | What it Means | Core Idea | Example |
|---|---|---|---|
| AI | Making computers act intelligently | The broad goal | A chess playing computer |
| Machine Learning | Teaching computers to learn from data | Learn patterns instead of rules | Predicting spam emails |
| Deep Learning | ML using multi-layered neural networks | Learns complex patterns automatically | Facial recognition |
| Generative AI | AI application focused on generating new content | Generates text, images, music, etc. | ChatGPT, DALL·E |
What’s next?
Our goal with Guidely is to create a community where anyone, regardless of background, can truly understand and grow with AI.
We do the heavy lifting: researching and testing. Then we collaborate with experienced AI engineers to challenge and sharpen our insights. The result? Clear and engaging guides that make complex AI concepts feel approachable → See our guide on Neural Networks.
Working on these guides takes an incredible amount of effort. You can support us by sharing this with anyone who might find it useful.
Furthermore, we take our time with the long-form guides — so we do not put a lot of them out very often. As we work on a guide, we share snippets on LinkedIn and X. Please follow us to catch them.
Skip to
Enjoyed the read? Help us spread the word — say something nice!